Literature Review
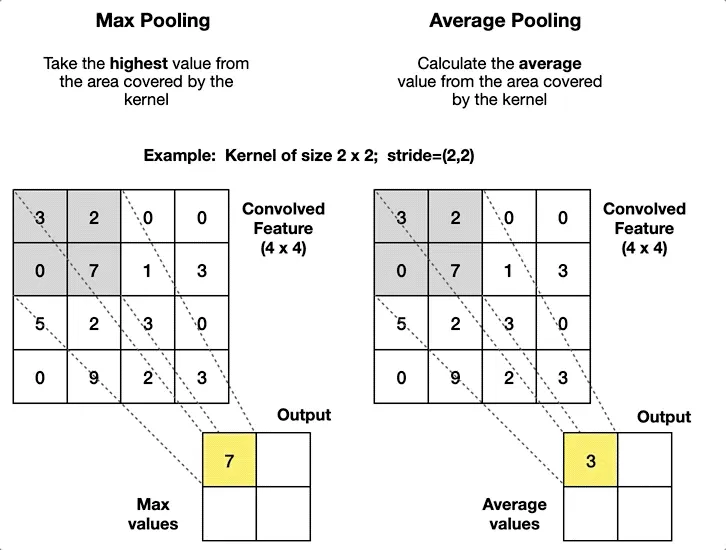
Large Batch and Patch Size Training for Medical Image Segmentation:
This article highlights the performance improvements gained by adjusting patch and batch sizes, suggesting that larger patches improve segmentation accuracy up to a certain limit, beyond which performance plateaus or even decreases.
Adaptive pooling could be used to create variable patch sizes within a single image, enabling finer details in complex areas and larger patches for broader context in simpler areas.
By using adaptive pooling, you could manage patch sizes more dynamically, potentially overcoming the plateau effect observed with fixed large patch sizes.
This would ensure that each region of the image is analyzed at an optimal scale, leading to potentially higher accuracy without the drawbacks of uniform large patches.
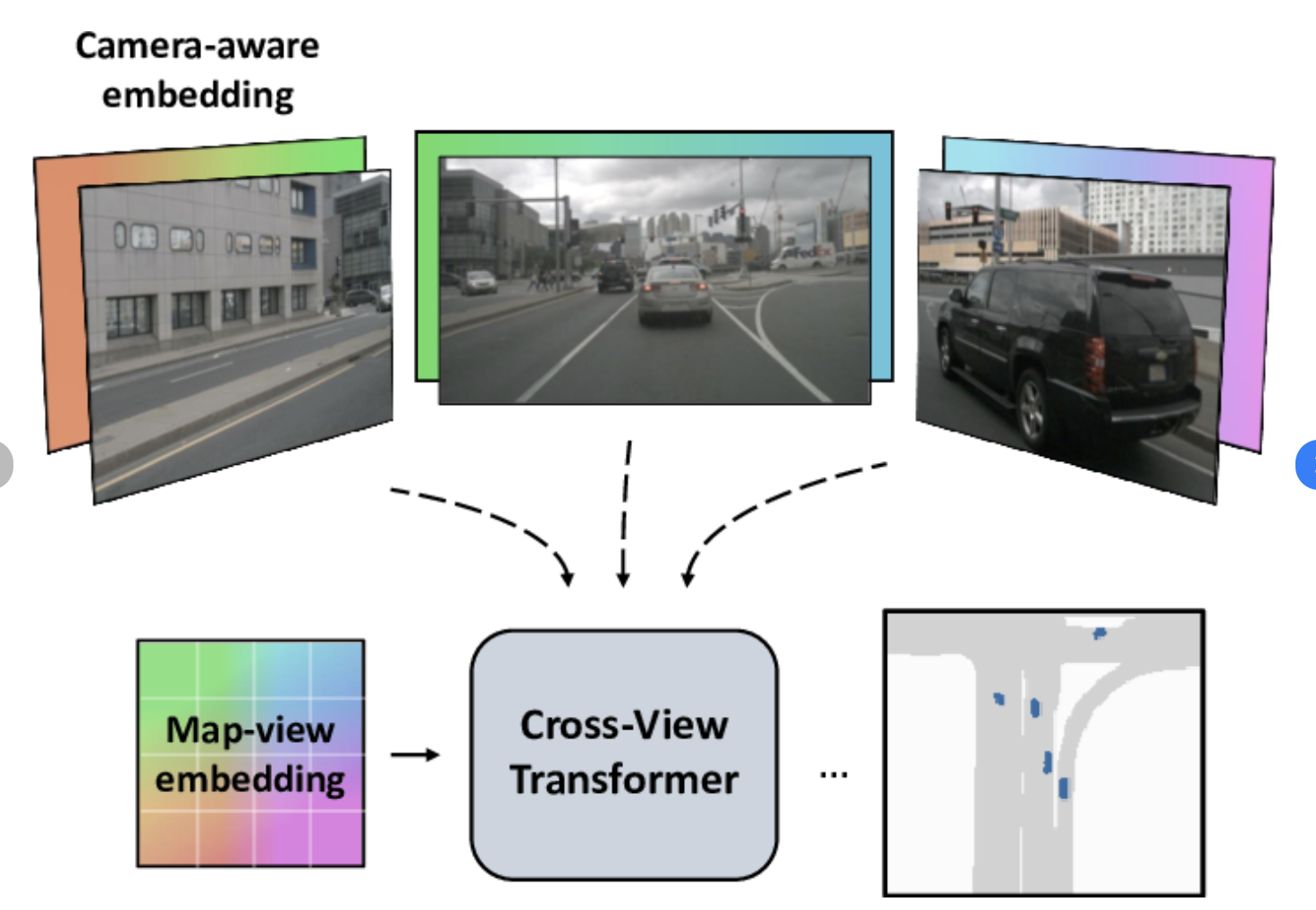
Purpose: Cross-view transformers are ideal for aligning images from different modalities (or stains) without exact pixel-level registration. They enable spatial feature alignment through learned transformations, which is helpful when the images are stained differently and thus might not naturally align perfectly.
Benefit: Using this alignment allows our algorithm to recognize similar regions across stains, orienting them correctly and enabling the same-region patches to be matched across the stains. The algorithm would learn to map similar features across images without requiring identical sizes, which suits our no-resize constraint.
How to Implement:
Input the Three Stains: For each patient’s tissue sample, create multi-resolution representations for each of the three stains (sox10, melana, and H&E).
Align Using Cross-View Transformers: Apply cross-view alignment to identify similar regions across stains by mapping corresponding features. This step ensures that the patches you sample come from the same tissue regions across the three stains.
Extract Aligned Patches: Use the aligned regions to sample patches that are similarly oriented and positioned, ensuring consistency.
Apply Controlled Padding (if Needed): Pad the patches to make them uniform in size, allowing them to be used in the classification model.
Summary: Ultimately, the multi-resolution network will capture different levels of detail from each stain, ensuring that both fine cellular structures and broader tissue architectures are represented. This helps to make the model robust to slight size or scale variations in patches. The cross-view alignment will allow our algorithm to “match” regions across different stains based on learned features rather than exact spatial coordinates. This is especially helpful when we have patches of different stains that aren’t perfectly aligned but should correspond to the same tissue region.
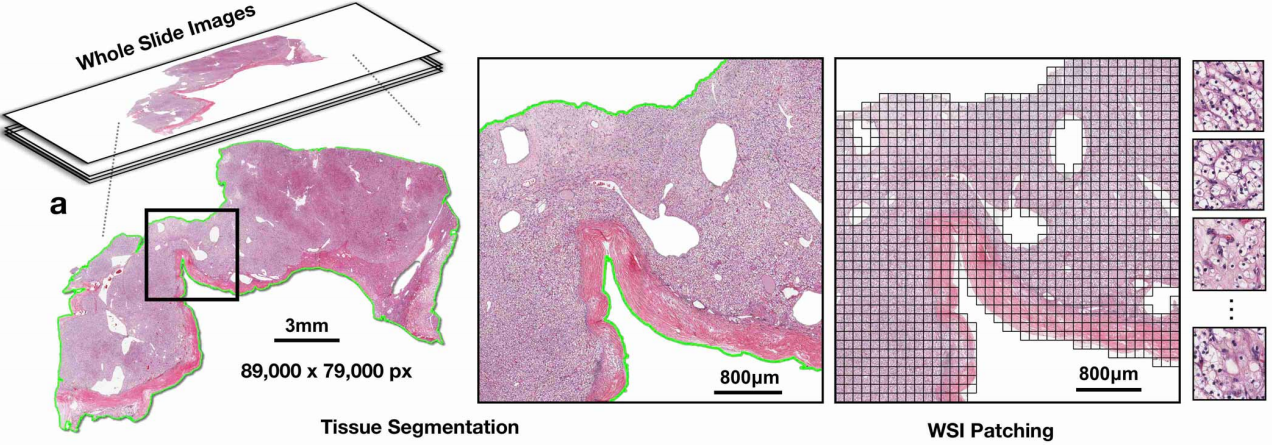
In medical imaging applications, image patches are usually square regions whose size can vary from 32 × 32 pixels up to 10,000 × 10,000 pixels (256 × 256 pixels is a typical patch size
Square Patches: Common Practice and Benefits
Square patches are popular due to their simplicity and compatibility with standard convolutional neural network (CNN) architectures. They provide balanced feature extraction and are easy to preprocess and resize.
Study Reference: A study on patch-based classification using CNNs found that square patches offered efficient, balanced spatial representation for deep learning models.
Rectangular Patches: Advantages and Considerations
Rectangular patches are beneficial for capturing elongated or directional structures in tissues, such as blood vessels or specific cellular arrangements. They can maximize context capture along a specific axis.
Study Reference: Research on adaptive patch extraction found that rectangular patches, when properly oriented, improved analysis accuracy for tissues with dominant directional features.
Comparative Analysis
Square patches are easier to integrate into standard CNNs and preprocessing workflows, making them suitable for general histopathological analysis. Rectangular patches, while more complex to implement, offer better feature representation for specific tissue structures.
CNNs and Image Classification:
Convolutional Neural Networks (CNNs) have emerged as a dominant architecture in the realm of image classification due to their capacity to capture hierarchical patterns in visual data. Their structure, characterized by convolutional layers, pooling layers, and fully connected layers, enables the effective extraction and learning of features such as edges, textures, and complex shapes. Image classification is critical in various applications, from medical imaging diagnostics to autonomous vehicle navigation and facial recognition technologies.
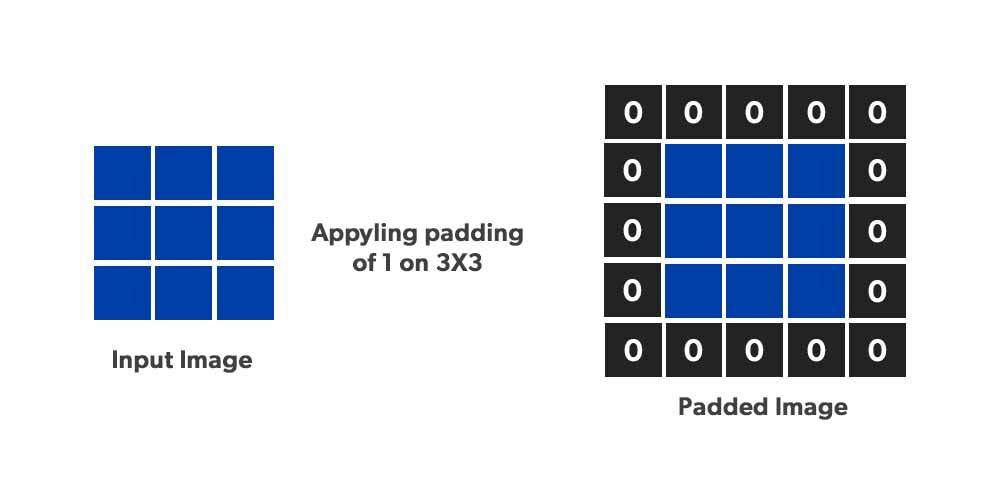
Role of Padding in CNNs:
Padding refers to the practice of adding extra pixels around the borders of an image before it is passed through a convolutional layer. This added border can be composed of zeros or other methods of pixel replication, and serves several important functions in the context of deep learning models. Padding affects how convolution operations treat the image boundaries, ensuring that every pixel, including those at the edges, receives the same level of processing as those in the center.
Types of Padding:
Valid Padding (No Padding):
- This type processes only the valid, central pixels of the image, avoiding the addition of extra pixels. The downside of valid padding is that it reduces the spatial dimensions of the image after each convolutional layer, potentially leading to loss of information and reduced feature maps.
Same Padding:
- Same padding involves adding pixels around the border such that the output feature map has the same width and height as the input. This type of padding ensures that spatial dimensions are maintained throughout the network, allowing for deeper architectures to operate without diminishing the feature map size.
Zero Padding:
- This is a specific type of same padding where the border pixels added are zeros. It is used to control the size of the output while ensuring that edge pixels contribute to feature extraction.
Reflection Padding:
Reflection padding is a type of padding where the pixel values along the borders of an image are mirrored, creating a natural extension of the image edges. This method is designed to preserve edge continuity, making it particularly beneficial for tasks where accurate edge processing is essential.
Visual Impact: The padded border reflects the nearest pixels from the original image, creating a seamless transition that better mimics natural image boundaries compared to zero padding.
Feature Extraction: Reflection padding enhances feature extraction by preserving the original edge information, allowing convolutional filters to process these pixels as part of the existing image. This continuity leads to stronger responses and better feature learning at the borders.
Use Cases and Benefits: Reflection padding is advantageous in scenarios where maintaining edge information is critical, such as in medical imaging or fine-grained image recognition tasks. Studies have demonstrated that using reflection padding can improve model performance, particularly for complex images where edge details carry significant information.
Impact of Padding on Image Classification Performance
Padding plays a critical role in maintaining the integrity of the data passed through CNNs and can significantly affect the model’s overall performance.
Preservation of Spatial Dimensions:
- Same padding is particularly valuable because it prevents the reduction of image size across layers. This preservation is crucial when working with complex and deep networks where retaining spatial dimensions is necessary for accurate feature extraction.
Reduction in Information Loss:
- Without padding, the edges of an image can receive less attention from convolutional layers, potentially leading to information loss. Padding mitigates this issue by providing a buffer around the image, ensuring that features at the borders are adequately processed and retained.
Improvement in Feature Extraction:
- Research has shown that padding enhances the network’s ability to detect edge-related features, contributing to a more holistic understanding of the input image.
Computational Cost:
- While padding ensures that the output feature map size remains the same as the input, it can increase computational complexity. Larger feature maps require more memory and processing power, especially in deep networks. This can impact the overall training time and computational cost of the model.
Padding References:
“The Impact of Padding on Image Classification by Using Pre-trained Convolutional Neural Networks” (2019): This study investigated the effect of pre-processing, specifically padding, on image classification using pre-trained CNN models. The authors proposed a padding pre-processing pipeline that improved classification performance on challenging images without the need for re-training the model or increasing the number of CNN parameters.
“Position, Padding and Predictions: A Deeper Look at Position Information in CNNs” (2024): This research explored how padding influences the encoding of position information in CNNs. The study revealed that zero padding drives CNNs to encode position information in their internal representations, while a lack of padding precludes position encoding. This finding suggests that padding not only affects spatial dimensions but also the way positional information is processed within the network.
“Effects of Boundary Conditions in Fully Convolutional Networks for Spatio-Temporal Physical Modeling” (2021): This study examined various padding strategies, including reflection padding, within the context of spatio-temporal physical modeling using fully convolutional networks. The researchers found that reflection padding significantly helped in preserving edge continuity and reduced boundary artifacts, resulting in improved network generalization and accuracy. This effect was particularly notable in tasks requiring precise edge information, such as fluid dynamics simulations.